From experiments to AI products. Grounded in a decade of scientific research. Integrates AI workflows. Ships AI tools.
Cornell Ph.D. in Biological & Environmental Engineering (DNA Materials Lab) — grounded in Chemistry and Computer Science — integrating AI into workflows and building AI-powered tools that make it out of the lab.
See how I work ↓Domain expertise is the foundation. Mastering AI elevates it to a new dimension.
How I Integrate AI into Research Workflows
From a 33-hour, 11 km² eDNA tracer campaign (~1,000 qPCR measurements; ~1,400 GPS coordinates) to a 100-day continuous nucleic-acid reactor, I use AI-assisted coding to turn raw outputs into reproducible analyses, publication figures, and structured reports.
Automated Reporting
Feed experiment design + raw qPCR data into a structured tracking report. No manual formatting.

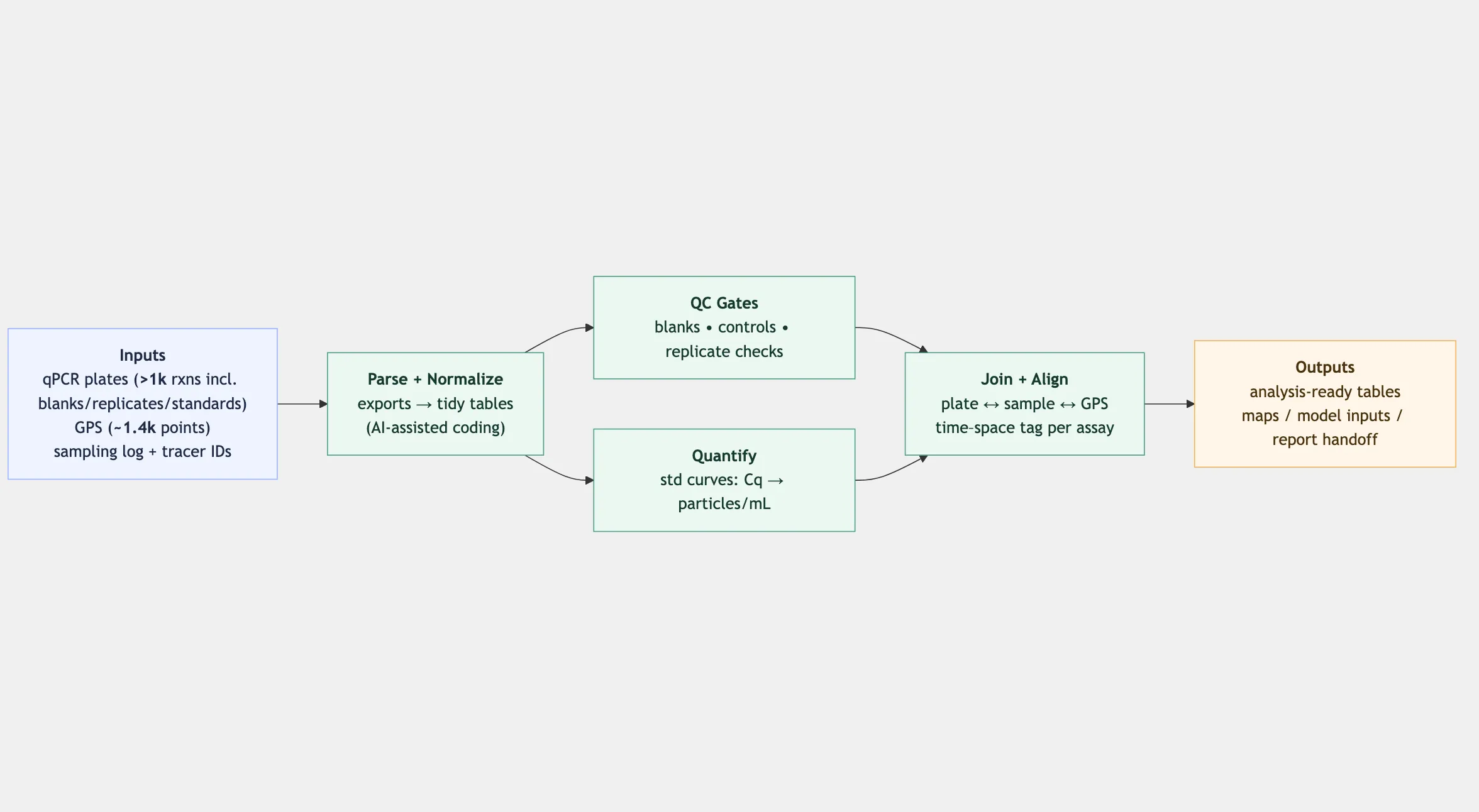
Data Pipeline
Automated a 33-hour field campaign pipeline. ~1,000 qPCR measurements, ~1,400 GPS coordinates — from raw to analysis-ready in minutes.
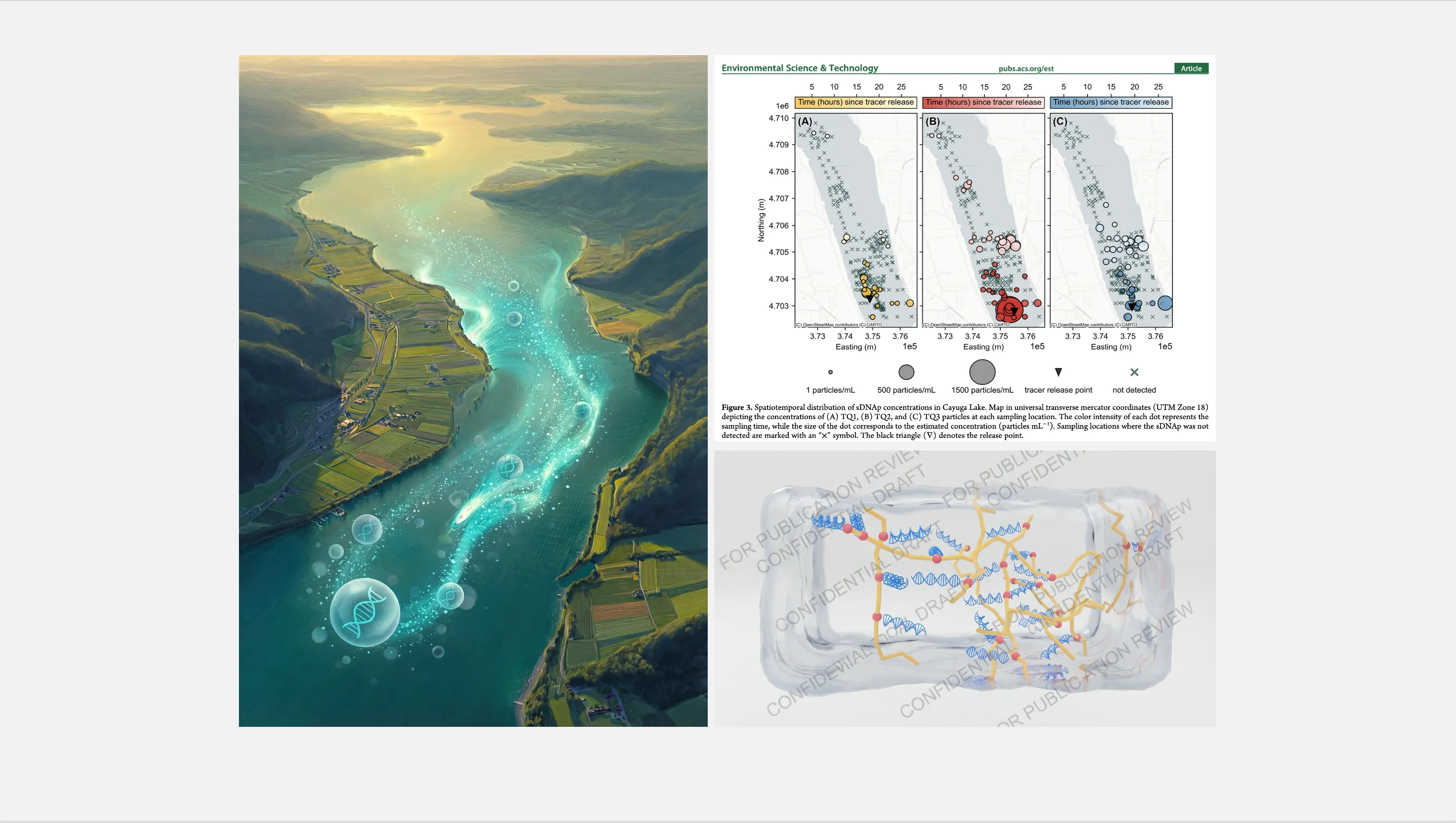
Scientific Visualization
Publication figures, journal cover art, and 3D molecular renders. ~20 Python scripts, all AI-assisted.
How I Build and Ship AI Tools
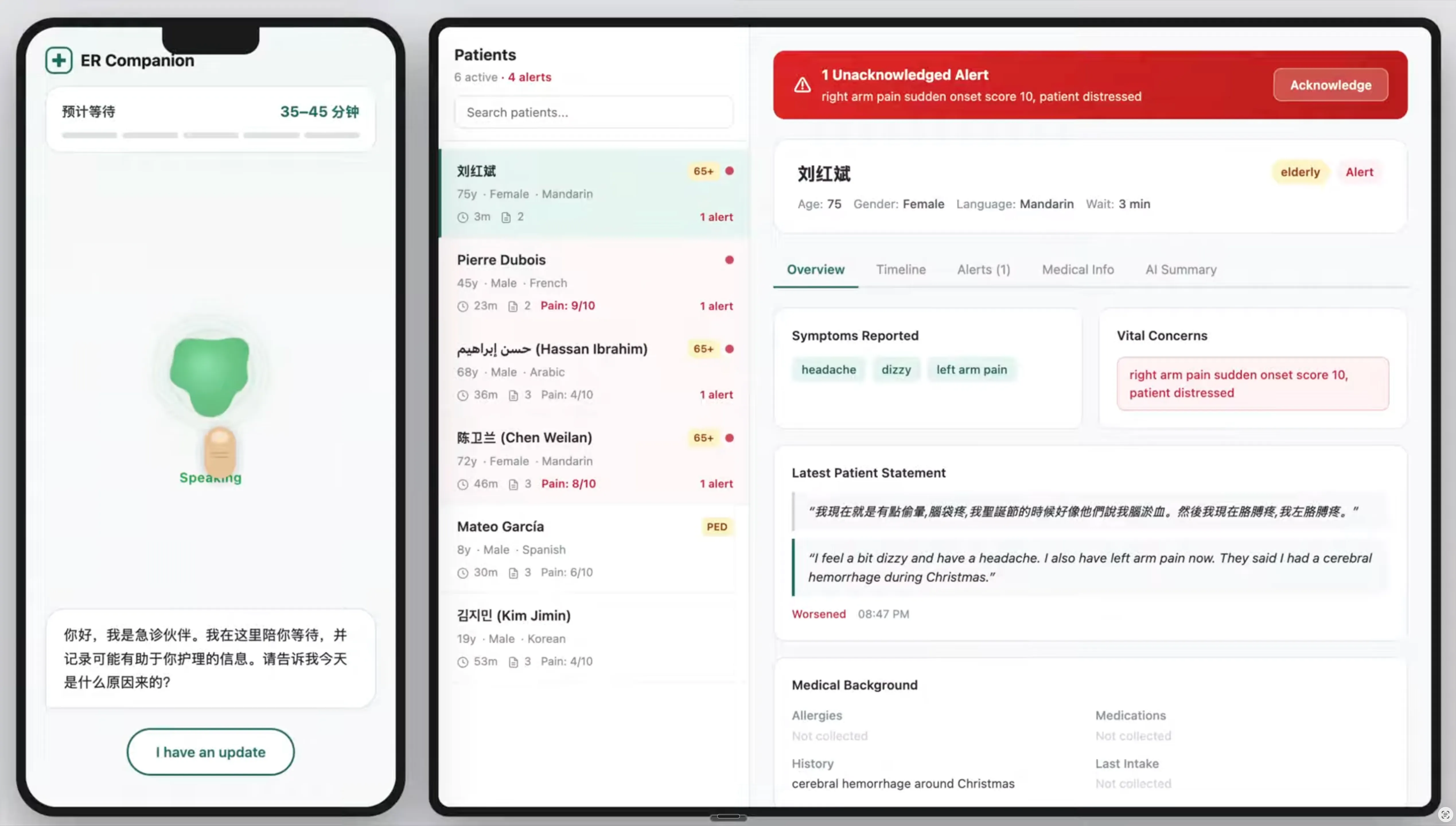

ER Companion (CareBridge)
155 million ED visits a year — non-English-speaking patients wait 5.4 min longer to be roomed and 15.6 min longer for disposition. We built the layer that stays: a voice pipeline in 8 languages that listens continuously, flags changes the moment they happen, and puts the patient's exact words — not an AI summary — in front of the nurse in real time. Paired with a wristband feeding fall detection and vitals into the same stream.
Best Hardware Prize, Cornell AI Health Hackathon · 8 languages · Real-time nurse dashboard · WCAG AA accessible
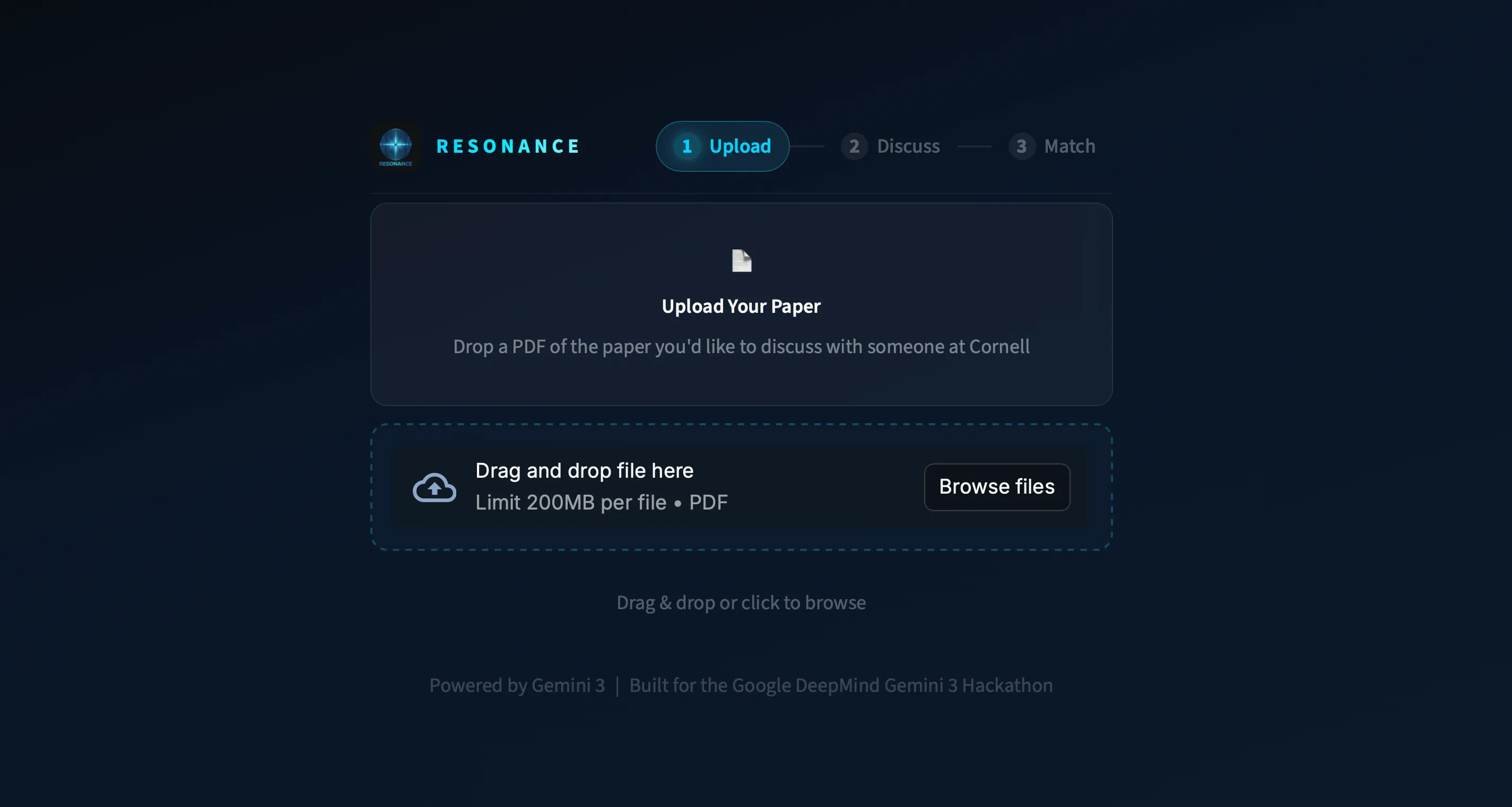
Resonance
The perfect person to discuss that paper with is probably right on your campus — you just don't know it yet. Upload it, chat with Gemini, and we'll connect you.
78% first-match accuracy · 230 Cornell researchers indexed · Hybrid FAISS + BM25 search
Echo (回响)
Reconnecting after a falling out is emotionally risky — you don't know if they're open to it, and one message can make things worse. Echo lets both people privately signal their intention first. Only when there's mutual openness does it reveal a match, so no one has to make the first move alone.
Double-blind matching · SMS verification · Gemini NVC message check · Real-time sync · EN/中文 · 988 crisis resources
CoBrain
WIPA shared, evidence-first brain for your lab. Upload PDFs, capture your group's definitions and standards, and ask questions to get cited, auditable answers — with built-in quality gates and refusal when evidence is thin.
How I Think About AI
"Domain judgment sets the direction; AI shortens the loop."
I don't treat AI like a reliable calculator or a colleague who "gets" what I mean. I treat it like a fast executor that's great at generating drafts, code, and alternatives — but still needs clear structure and careful checking. The work starts with me: I decide what question matters, break it into smaller steps, and define what a good answer should look like. Then I let the model run: write the first pass, explore options, refactor code, and surface patterns. Finally, I verify everything against the domain reality — controls, assumptions, edge cases — and only keep what holds up.
Teaching AI at Cornell
I design hands-on AI tooling modules for Cornell bioengineering undergrads. I co-taught one course (~45 students; ~50% of the content) and gave guest lectures in two others. The focus is practical: how to break a messy question into steps, use AI-assisted scripting to move faster, and still keep scientific checks in place.
BEE 3400 — AI Tooling Module
- ✓ Co-instructor (~50% of content) · ~45 students
- ✓ Labs: problem breakdown → AI-assisted scripting → data processing + visualization
AI Integration Module
- ✓ Built confidence-gated exam grading and automated notebook assessment
- ✓ Reduced grading turnaround to <24 hours
From the Lecture Slides


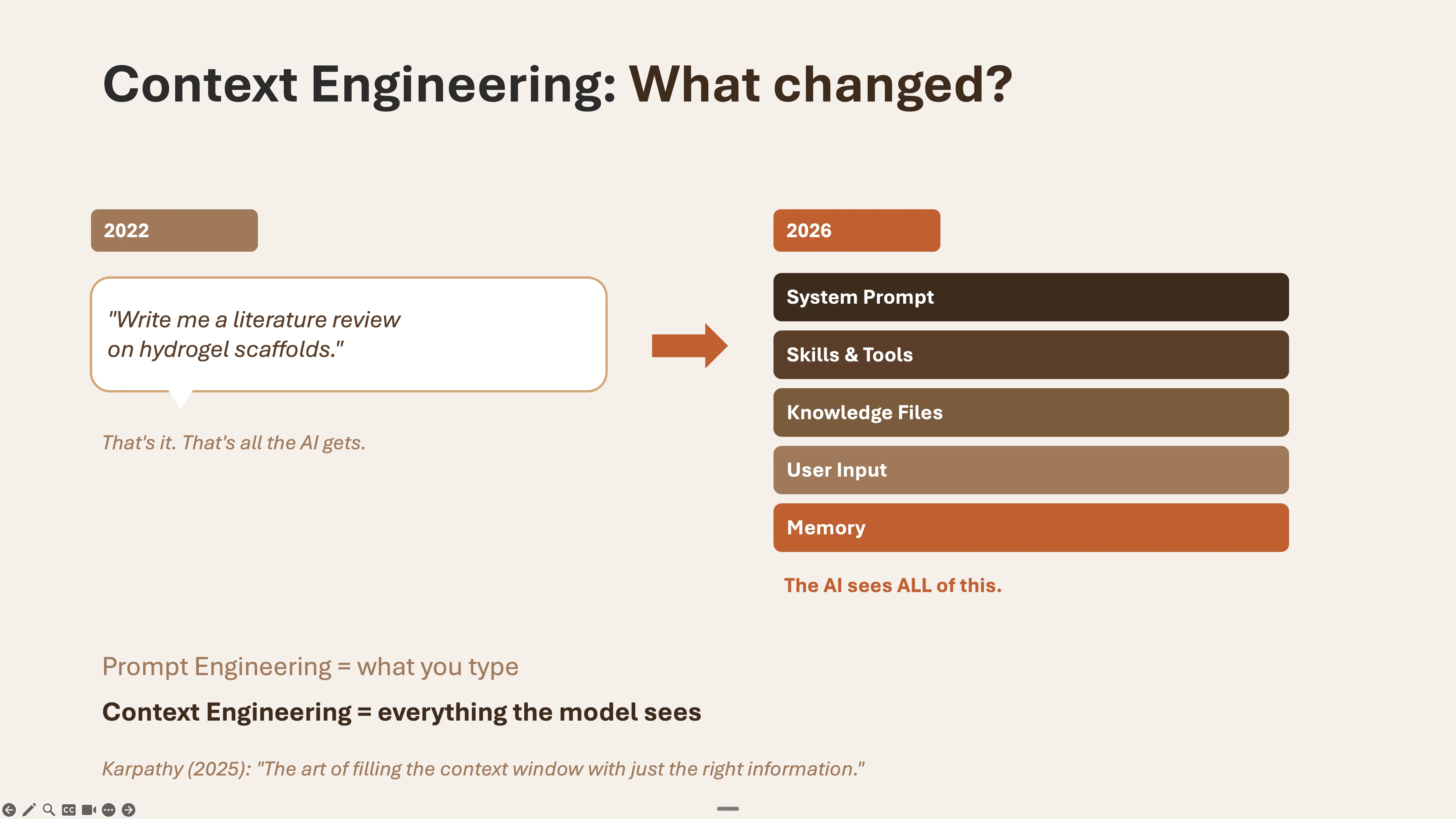
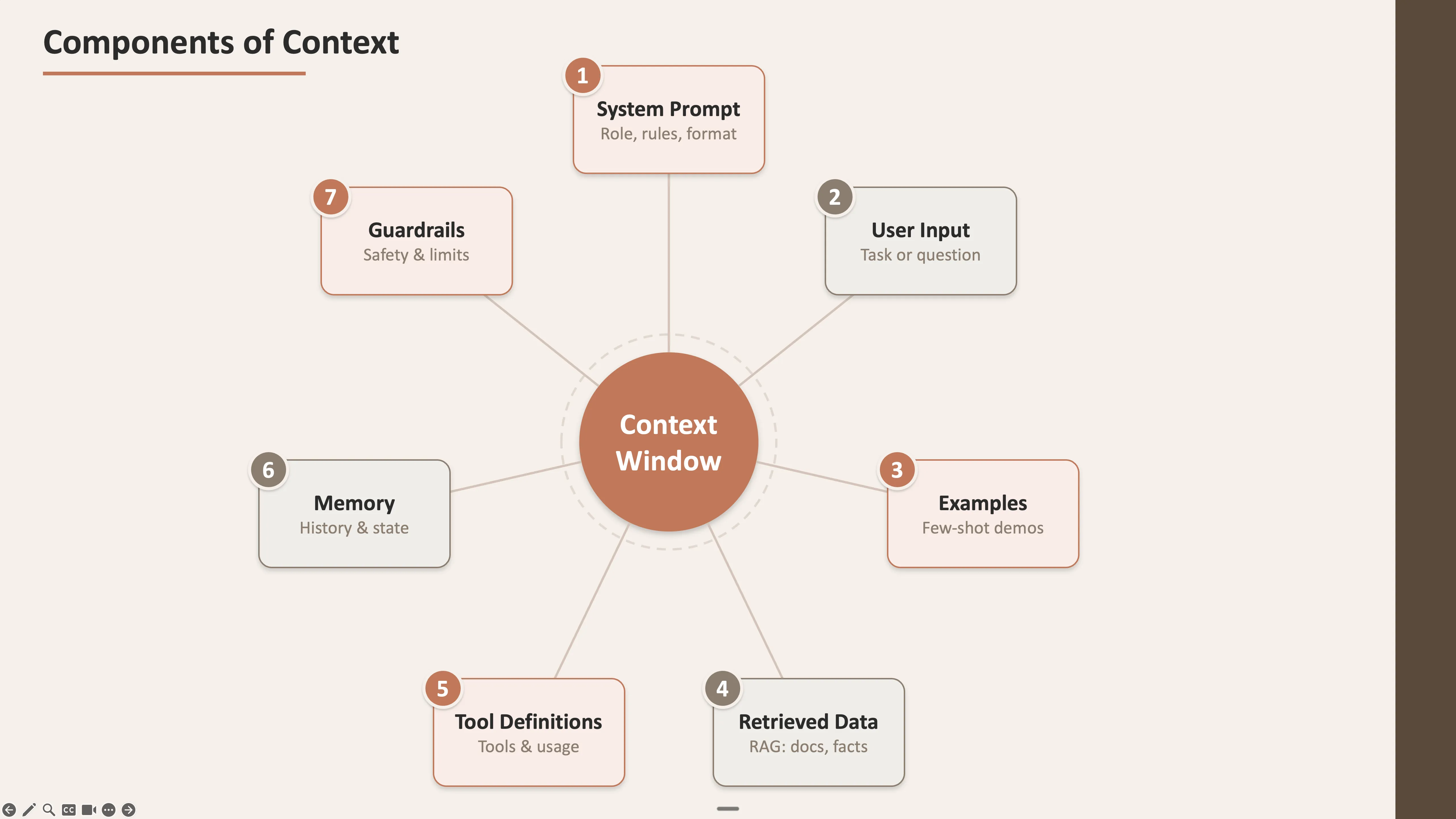
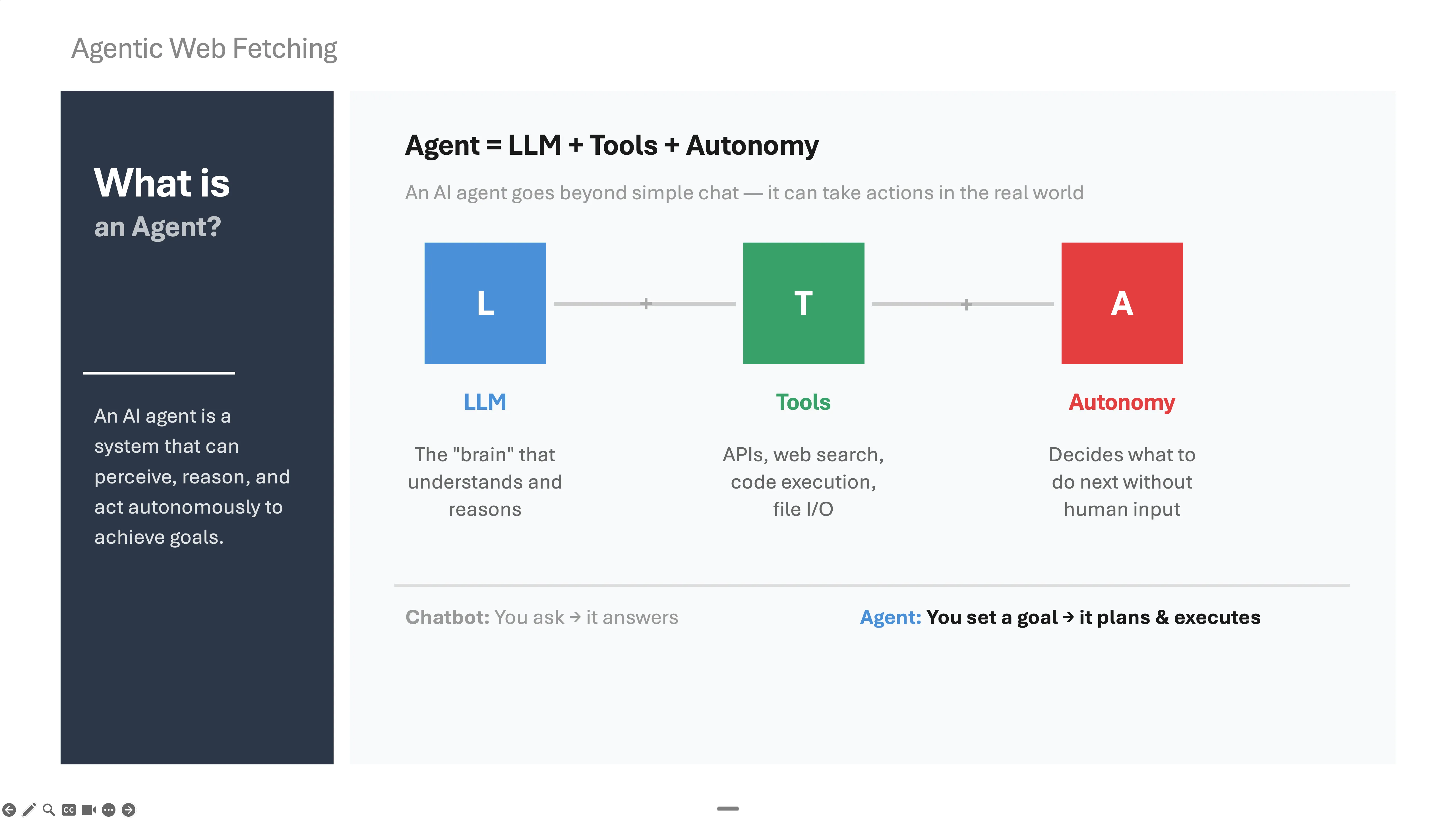




Click any slide to view full size
AI Fluency Index
The AI Fluency Index is a research framework developed by Professors Rick Dakan and Joseph Feller in collaboration with Anthropic. It measures 11 observable behaviors across three dimensions — Description, Delegation, and Discernment — that characterize effective human-AI collaboration, baselined against 9,830 Claude.ai conversations. Below is my personal profile scored across ~40 of my own conversations.
Discernment score (63%) is 3.5x the population average — fact-checking, questioning reasoning, and catching missing context at 3–4x typical rates.
Framework: Anthropic 4D AI Fluency (Dakan & Feller, 2026). Baselines from 9,830 conversations.
Get Your Own AI Fluency Index
I engineered the prompt below from the original research paper — it turns a static publication into a reproducible self-assessment anyone can run. Paste it into a new Claude.ai conversation to generate your own dashboard.